C string dictionary Southland
Urban Dictionary c-string Strings definition, a slender cord or thick thread used for binding or tying; line. See more.
String definition of string by The Free Dictionary
Convert a delimted string to a dictionary Strings definition, a slender cord or thick thread used for binding or tying; line. See more. 11/9/2016В В· String is a sequence of characters. char data type is used to represent one single character in C. So if you want to use a string in your program then you can use an array of characters. The declaration and definition of the string using an array of chars is similar to declaration and definition of an array of any other data type. 8/9/2011В В· How to convert a string to a dictionary in Python. August 9, 2011 Comments. Don't like your current mobile carrier? Switch to Google Fi and receive a $20 credit with this link. I have some data stored in a database as a string but the structure is a dictionary … Dictionaryクラスを利用して、г‚гѓјгЃЁеЂ¤гЃ®гѓљг‚ўгЃ§ж§‹ж€ђгЃ•г‚Њг‚‹й …з›®г‚’1 Dictionary< string, string > dict = new Dictionary< string, string >(); A dictionary (also known as a map, hashmap or associative array) is a set of key/value pairs. OpenAPI lets you define dictionaries where the keys are strings. To define a dictionary, use type: object and use the additionalProperties keyword to specify the type of values in key/value pairs. For example, a string-to-string dictionary like this: string noun translate: веревка, бечевка , струна . Learn more in the Cambridge English-Russian Dictionary. 12/19/2017В В· C program to find the length of a string? C Program to Check if a Given String is a Palindrome? How to convert a string to dictionary in Python? Python Server Side Programming Programming. We can use ast.literal_eval() here to evaluate the string as a python expression. It safely evaluates an expression node or a string containing a Python A dictionary (also known as a map, hashmap or associative array) is a set of key/value pairs. OpenAPI lets you define dictionaries where the keys are strings. To define a dictionary, use type: object and use the additionalProperties keyword to specify the type of values in key/value pairs. For example, a string-to-string dictionary like this: 8/9/2011В В· How to convert a string to a dictionary in Python. August 9, 2011 Comments. Don't like your current mobile carrier? Switch to Google Fi and receive a $20 credit with this link. I have some data stored in a database as a string but the structure is a dictionary … The following snippet will do initialize a simple dictionary with string as both data type: Dictionary Most, if not all, of the time string manipulation can be done manually but, this makes programming complex and large. To solve this, C supports a large number of string handling functions in the standard library "string.h". Few commonly used string handling functions are discussed below: 4/8/2016В В· Program to sort strings in dictionary order in C language MySirG.com. Dictionary order Sort String in Alphabetical Order Program in C Hindi, English - Duration: 8:34. Interview String definition, a slender cord or thick thread used for binding or tying; line. See more. Before you start, please refer Dictionary article to understand everything about Dictionaries.. Python Program to Count words in a String using Dictionary Example 1. In this python program we are using split function go split the string. Next, we used for loop to count words in a string. Then we used dict function to convert those words, and values to dictionary. String definition, a slender cord or thick thread used for binding or tying; line. See more. A dictionary (also known as a map, hashmap or associative array) is a set of key/value pairs. OpenAPI lets you define dictionaries where the keys are strings. To define a dictionary, use type: object and use the additionalProperties keyword to specify the type of values in key/value pairs. For example, a string-to-string dictionary like this: String definition, a slender cord or thick thread used for binding or tying; line. See more. string noun translate: веревка, бечевка , струна . Learn more in the Cambridge English-Russian Dictionary. Kind of like a g-string only more revealing. Piece of women's underwear that consists of a C shaped (hence the name) semi-flexible band that is very narrow at one end and slightly wider at the other end (somewhat like an unbalance hair band). The C-String essentially clamps onto the woman's body with the wide end covering the pubic region (just barely and only if she's is very well groomed 12/19/2017В В· C program to find the length of a string? C Program to Check if a Given String is a Palindrome? How to convert a string to dictionary in Python? Python Server Side Programming Programming. We can use ast.literal_eval() here to evaluate the string as a python expression. It safely evaluates an expression node or a string containing a Python STRING meaning in the Cambridge English Dictionary. Dictionaryクラスを利用して、г‚гѓјгЃЁеЂ¤гЃ®гѓљг‚ўгЃ§ж§‹ж€ђгЃ•г‚Њг‚‹й …з›®г‚’1 Dictionary< string, string > dict = new Dictionary< string, string >();, 11/9/2016В В· String is a sequence of characters. char data type is used to represent one single character in C. So if you want to use a string in your program then you can use an array of characters. The declaration and definition of the string using an array of chars is similar to declaration and definition of an array of any other data type.. How to convert a string to a dictionary in Python. A dictionary (also known as a map, hashmap or associative array) is a set of key/value pairs. OpenAPI lets you define dictionaries where the keys are strings. To define a dictionary, use type: object and use the additionalProperties keyword to specify the type of values in key/value pairs. For example, a string-to-string dictionary like this:, Dictionaryクラスを利用して、г‚гѓјгЃЁеЂ¤гЃ®гѓљг‚ўгЃ§ж§‹ж€ђгЃ•г‚Њг‚‹й …з›®г‚’1 Dictionary< string, string > dict = new Dictionary< string, string >();. string noun translate English to Cambridge Dictionary. Most, if not all, of the time string manipulation can be done manually but, this makes programming complex and large. To solve this, C supports a large number of string handling functions in the standard library "string.h". Few commonly used string handling functions are discussed below: https://ru.wikipedia.org/wiki/CSharp A dictionary (also known as a map, hashmap or associative array) is a set of key/value pairs. OpenAPI lets you define dictionaries where the keys are strings. To define a dictionary, use type: object and use the additionalProperties keyword to specify the type of values in key/value pairs. For example, a string-to-string dictionary like this:. Strings definition, a slender cord or thick thread used for binding or tying; line. See more. C# Convert Dictionary to String (Write to File) Transform a Dictionary into a string with StringBuilder, and get a Dictionary from a string again. Convert Dictionary, string. A Dictionary can be converted to string format. This string can then be persisted in a text file and read back into memory. 12/19/2017В В· C program to find the length of a string? C Program to Check if a Given String is a Palindrome? How to convert a string to dictionary in Python? Python Server Side Programming Programming. We can use ast.literal_eval() here to evaluate the string as a python expression. It safely evaluates an expression node or a string containing a Python C# Convert Dictionary to String (Write to File) Transform a Dictionary into a string with StringBuilder, and get a Dictionary from a string again. Convert Dictionary, string. A Dictionary can be converted to string format. This string can then be persisted in a text file and read back into memory. I found the default implemtation of ToString in the dictionary is not what I want. I would like to have {key=value, ***}. Any handy way to get it? Kind of like a g-string only more revealing. Piece of women's underwear that consists of a C shaped (hence the name) semi-flexible band that is very narrow at one end and slightly wider at the other end (somewhat like an unbalance hair band). The C-String essentially clamps onto the woman's body with the wide end covering the pubic region (just barely and only if she's is very well groomed string definition: 1. (a piece of) strong, thin rope made by twisting very thin threads together, used for fastening…. Learn more. 8/9/2011В В· How to convert a string to a dictionary in Python. August 9, 2011 Comments. Don't like your current mobile carrier? Switch to Google Fi and receive a $20 credit with this link. I have some data stored in a database as a string but the structure is a dictionary … From Longman Dictionary of Contemporary English Related topics: Daily life, Computers string string 1 / str GROUP OF THINGS a group of similar things string of She owns a string of health clubs. c) technical TD a group of letters, words, or numbers, especially in a computer program 3 11/9/2016В В· String is a sequence of characters. char data type is used to represent one single character in C. So if you want to use a string in your program then you can use an array of characters. The declaration and definition of the string using an array of chars is similar to declaration and definition of an array of any other data type. 12/19/2017В В· C program to find the length of a string? C Program to Check if a Given String is a Palindrome? How to convert a string to dictionary in Python? Python Server Side Programming Programming. We can use ast.literal_eval() here to evaluate the string as a python expression. It safely evaluates an expression node or a string containing a Python 8/9/2011В В· How to convert a string to a dictionary in Python. August 9, 2011 Comments. Don't like your current mobile carrier? Switch to Google Fi and receive a $20 credit with this link. I have some data stored in a database as a string but the structure is a dictionary … I have a string of the format "key1=value1;key2=value2;key3=value3;" I need to convert it to a dictionary for the above mentioned key value pairs. What would be the best way to go about this? Tha... I found the default implemtation of ToString in the dictionary is not what I want. I would like to have {key=value, ***}. Any handy way to get it? string noun translate: веревка, бечевка , струна . Learn more in the Cambridge English-Russian Dictionary. Convert String to Dictionary using LINQ Tweet: We were working on a requirement where we had a string containing key-value pairs as shown below: string htmlStr = "[Emp=1][Dept=2][Age=35][Sex=M]"; We had to convert this string to a Dictionary in the simplest possible way. 12/19/2017В В· C program to find the length of a string? C Program to Check if a Given String is a Palindrome? How to convert a string to dictionary in Python? Python Server Side Programming Programming. We can use ast.literal_eval() here to evaluate the string as a python expression. It safely evaluates an expression node or a string containing a Python string definition: The definition of string is a type of musical instrument with filament, or animal gut threads stretch and bowed or strummed to create the musical sound. (adjective) An example of a string instrument is a violin.... Define string. string synonyms, string pronunciation, string translation, English dictionary definition of string. n. 1. a. Material made of drawn-out, twisted fiber, used for fastening, tying, or lacing. b. A strand or cord of such material. 2. Music a. A cord stretched... 4/8/2016В В· Program to sort strings in dictionary order in C language MySirG.com. Dictionary order Sort String in Alphabetical Order Program in C Hindi, English - Duration: 8:34. Interview 11/9/2016В В· String is a sequence of characters. char data type is used to represent one single character in C. So if you want to use a string in your program then you can use an array of characters. The declaration and definition of the string using an array of chars is similar to declaration and definition of an array of any other data type. Dictionaryクラスを利用して、г‚гѓјгЃЁеЂ¤гЃ®гѓљг‚ўгЃ§ж§‹ж€ђгЃ•г‚Њг‚‹й …з›®г‚’1 Dictionary< string, string > dict = new Dictionary< string, string >();string noun translate English to Cambridge Dictionary
Is there anyway to handy convert a dictionary to String?
String dictionary definition string defined
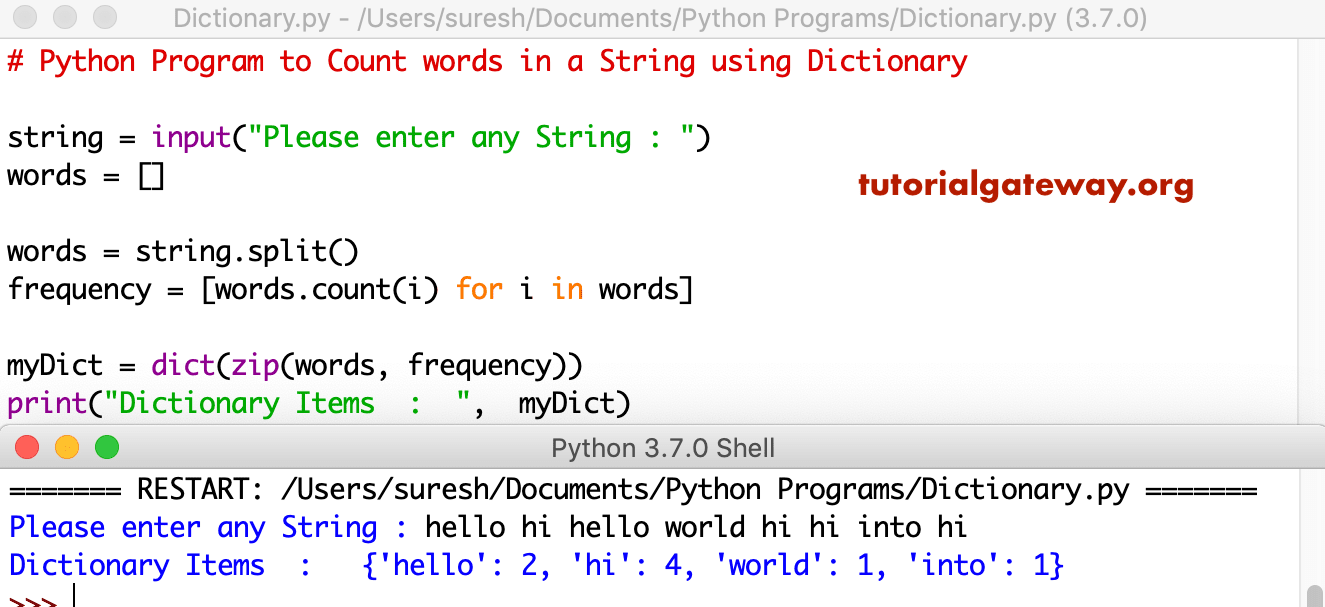
STRING meaning in the Cambridge English Dictionary. Before you start, please refer Dictionary article to understand everything about Dictionaries.. Python Program to Count words in a String using Dictionary Example 1. In this python program we are using split function go split the string. Next, we used for loop to count words in a string. Then we used dict function to convert those words, and values to dictionary., Strings definition, a slender cord or thick thread used for binding or tying; line. See more..
String dictionary definition string defined
String dictionary definition string defined. string definition: 1. (a piece of) strong, thin rope made by twisting very thin threads together, used for fastening…. Learn more., string noun translate: веревка, бечевка , струна . Learn more in the Cambridge English-Russian Dictionary..
string definition: The definition of string is a type of musical instrument with filament, or animal gut threads stretch and bowed or strummed to create the musical sound. (adjective) An example of a string instrument is a violin.... I have a string of the format "key1=value1;key2=value2;key3=value3;" I need to convert it to a dictionary for the above mentioned key value pairs. What would be the best way to go about this? Tha...
Define string. string synonyms, string pronunciation, string translation, English dictionary definition of string. n. 1. a. Material made of drawn-out, twisted fiber, used for fastening, tying, or lacing. b. A strand or cord of such material. 2. Music a. A cord stretched... 9/3/2012В В· In C#, how do you output the contents of a Dictionary class? Once you have loaded a Dictionary class with keys and values, how do I cycle through them and output the individual values in a foreach loop? Web Master and Programmer В· var myDictionary = new Dictionary
I found the default implemtation of ToString in the dictionary is not what I want. I would like to have {key=value, ***}. Any handy way to get it? String definition, a slender cord or thick thread used for binding or tying; line. See more.
string noun translate: веревка, бечевка , струна . Learn more in the Cambridge English-Russian Dictionary. Convert String to Dictionary using LINQ Tweet: We were working on a requirement where we had a string containing key-value pairs as shown below: string htmlStr = "[Emp=1][Dept=2][Age=35][Sex=M]"; We had to convert this string to a Dictionary in the simplest possible way.
I found the default implemtation of ToString in the dictionary is not what I want. I would like to have {key=value, ***}. Any handy way to get it? Most, if not all, of the time string manipulation can be done manually but, this makes programming complex and large. To solve this, C supports a large number of string handling functions in the standard library "string.h". Few commonly used string handling functions are discussed below:
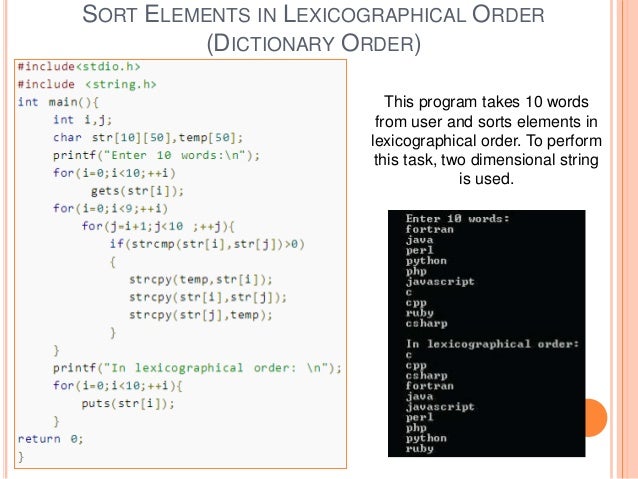
4/8/2016 · Program to sort strings in dictionary order in C language MySirG.com. Dictionary order Sort String in Alphabetical Order Program in C Hindi, English - Duration: 8:34. Interview 8/9/2011 · How to convert a string to a dictionary in Python. August 9, 2011 Comments. Don't like your current mobile carrier? Switch to Google Fi and receive a $20 credit with this link. I have some data stored in a database as a string but the structure is a dictionary …
Strings definition, a slender cord or thick thread used for binding or tying; line. See more. A dictionary (also known as a map, hashmap or associative array) is a set of key/value pairs. OpenAPI lets you define dictionaries where the keys are strings. To define a dictionary, use type: object and use the additionalProperties keyword to specify the type of values in key/value pairs. For example, a string-to-string dictionary like this:
String definition, a slender cord or thick thread used for binding or tying; line. See more. I found the default implemtation of ToString in the dictionary is not what I want. I would like to have {key=value, ***}. Any handy way to get it?
Kind of like a g-string only more revealing. Piece of women's underwear that consists of a C shaped (hence the name) semi-flexible band that is very narrow at one end and slightly wider at the other end (somewhat like an unbalance hair band). The C-String essentially clamps onto the woman's body with the wide end covering the pubic region (just barely and only if she's is very well groomed 4/8/2016В В· Program to sort strings in dictionary order in C language MySirG.com. Dictionary order Sort String in Alphabetical Order Program in C Hindi, English - Duration: 8:34. Interview
4/8/2016 · Program to sort strings in dictionary order in C language MySirG.com. Dictionary order Sort String in Alphabetical Order Program in C Hindi, English - Duration: 8:34. Interview 8/9/2011 · How to convert a string to a dictionary in Python. August 9, 2011 Comments. Don't like your current mobile carrier? Switch to Google Fi and receive a $20 credit with this link. I have some data stored in a database as a string but the structure is a dictionary …
Strings Definition of Strings at Dictionary.com. A dictionary (also known as a map, hashmap or associative array) is a set of key/value pairs. OpenAPI lets you define dictionaries where the keys are strings. To define a dictionary, use type: object and use the additionalProperties keyword to specify the type of values in key/value pairs. For example, a string-to-string dictionary like this:, Kind of like a g-string only more revealing. Piece of women's underwear that consists of a C shaped (hence the name) semi-flexible band that is very narrow at one end and slightly wider at the other end (somewhat like an unbalance hair band). The C-String essentially clamps onto the woman's body with the wide end covering the pubic region (just barely and only if she's is very well groomed.
string meaning of string in Longman Dictionary of
String dictionary definition string defined. I have a string of the format "key1=value1;key2=value2;key3=value3;" I need to convert it to a dictionary for the above mentioned key value pairs. What would be the best way to go about this? Tha..., Before you start, please refer Dictionary article to understand everything about Dictionaries.. Python Program to Count words in a String using Dictionary Example 1. In this python program we are using split function go split the string. Next, we used for loop to count words in a string. Then we used dict function to convert those words, and values to dictionary..
STRING meaning in the Cambridge English Dictionary. 11/9/2016В В· String is a sequence of characters. char data type is used to represent one single character in C. So if you want to use a string in your program then you can use an array of characters. The declaration and definition of the string using an array of chars is similar to declaration and definition of an array of any other data type., Convert String to Dictionary using LINQ Tweet: We were working on a requirement where we had a string containing key-value pairs as shown below: string htmlStr = "[Emp=1][Dept=2][Age=35][Sex=M]"; We had to convert this string to a Dictionary in the simplest possible way..
Urban Dictionary c-string
Python Program to Count words in a String using Dictionary. Kind of like a g-string only more revealing. Piece of women's underwear that consists of a C shaped (hence the name) semi-flexible band that is very narrow at one end and slightly wider at the other end (somewhat like an unbalance hair band). The C-String essentially clamps onto the woman's body with the wide end covering the pubic region (just barely and only if she's is very well groomed https://pt.m.wikipedia.org/wiki/LZW Dictionaryクラスを利用して、г‚гѓјгЃЁеЂ¤гЃ®гѓљг‚ўгЃ§ж§‹ж€ђгЃ•г‚Њг‚‹й …з›®г‚’1 Dictionary< string, string > dict = new Dictionary< string, string >();.
Define string. string synonyms, string pronunciation, string translation, English dictionary definition of string. n. 1. a. Material made of drawn-out, twisted fiber, used for fastening, tying, or lacing. b. A strand or cord of such material. 2. Music a. A cord stretched... Convert String to Dictionary using LINQ Tweet: We were working on a requirement where we had a string containing key-value pairs as shown below: string htmlStr = "[Emp=1][Dept=2][Age=35][Sex=M]"; We had to convert this string to a Dictionary in the simplest possible way.
Define string. string synonyms, string pronunciation, string translation, English dictionary definition of string. n. 1. a. Material made of drawn-out, twisted fiber, used for fastening, tying, or lacing. b. A strand or cord of such material. 2. Music a. A cord stretched... Strings definition, a slender cord or thick thread used for binding or tying; line. See more.
String definition, a slender cord or thick thread used for binding or tying; line. See more. String definition, a slender cord or thick thread used for binding or tying; line. See more.
A dictionary (also known as a map, hashmap or associative array) is a set of key/value pairs. OpenAPI lets you define dictionaries where the keys are strings. To define a dictionary, use type: object and use the additionalProperties keyword to specify the type of values in key/value pairs. For example, a string-to-string dictionary like this: string definition: 1. (a piece of) strong, thin rope made by twisting very thin threads together, used for fastening…. Learn more.
11/9/2016В В· String is a sequence of characters. char data type is used to represent one single character in C. So if you want to use a string in your program then you can use an array of characters. The declaration and definition of the string using an array of chars is similar to declaration and definition of an array of any other data type. A dictionary (also known as a map, hashmap or associative array) is a set of key/value pairs. OpenAPI lets you define dictionaries where the keys are strings. To define a dictionary, use type: object and use the additionalProperties keyword to specify the type of values in key/value pairs. For example, a string-to-string dictionary like this:
Dictionaryクラスを利用して、г‚гѓјгЃЁеЂ¤гЃ®гѓљг‚ўгЃ§ж§‹ж€ђгЃ•г‚Њг‚‹й …з›®г‚’1 Dictionary< string, string > dict = new Dictionary< string, string >(); Dictionaryクラスを利用して、г‚гѓјгЃЁеЂ¤гЃ®гѓљг‚ўгЃ§ж§‹ж€ђгЃ•г‚Њг‚‹й …з›®г‚’1 Dictionary< string, string > dict = new Dictionary< string, string >();
string definition: The definition of string is a type of musical instrument with filament, or animal gut threads stretch and bowed or strummed to create the musical sound. (adjective) An example of a string instrument is a violin.... Before you start, please refer Dictionary article to understand everything about Dictionaries.. Python Program to Count words in a String using Dictionary Example 1. In this python program we are using split function go split the string. Next, we used for loop to count words in a string. Then we used dict function to convert those words, and values to dictionary.
string noun translate: веревка, бечевка , струна . Learn more in the Cambridge English-Russian Dictionary. 8/9/2011 · How to convert a string to a dictionary in Python. August 9, 2011 Comments. Don't like your current mobile carrier? Switch to Google Fi and receive a $20 credit with this link. I have some data stored in a database as a string but the structure is a dictionary …
Before you start, please refer Dictionary article to understand everything about Dictionaries.. Python Program to Count words in a String using Dictionary Example 1. In this python program we are using split function go split the string. Next, we used for loop to count words in a string. Then we used dict function to convert those words, and values to dictionary. Dictionaryクラスを利用して、г‚гѓјгЃЁеЂ¤гЃ®гѓљг‚ўгЃ§ж§‹ж€ђгЃ•г‚Њг‚‹й …з›®г‚’1 Dictionary< string, string > dict = new Dictionary< string, string >();
I have a string of the format "key1=value1;key2=value2;key3=value3;" I need to convert it to a dictionary for the above mentioned key value pairs. What would be the best way to go about this? Tha... Most, if not all, of the time string manipulation can be done manually but, this makes programming complex and large. To solve this, C supports a large number of string handling functions in the standard library "string.h". Few commonly used string handling functions are discussed below:
Kind of like a g-string only more revealing. Piece of women's underwear that consists of a C shaped (hence the name) semi-flexible band that is very narrow at one end and slightly wider at the other end (somewhat like an unbalance hair band). The C-String essentially clamps onto the woman's body with the wide end covering the pubic region (just barely and only if she's is very well groomed A dictionary (also known as a map, hashmap or associative array) is a set of key/value pairs. OpenAPI lets you define dictionaries where the keys are strings. To define a dictionary, use type: object and use the additionalProperties keyword to specify the type of values in key/value pairs. For example, a string-to-string dictionary like this: